
Kubernetes Pod Scheduling Explained: Taints, Tolerations, and Node Affinity

Introduction
Managing Kubernetes clusters sometimes involves precise control over pod placement to ensure that workloads are appropriately distributed across certain nodes. Kubernetes offers several ways for this, including taints, tolerations, and node affinity. In this post will explore each method, provide use cases, and demonstrate how to combine them for optimal pod scheduling.
We’ll tackle a specific problem: scheduling specific pods to specific nodes and ensuring no other pods are placed on these specialized nodes.
Believe me, it's not fully obvious at the first attempt.
Some terminlogy used in the article
Optimized Node:
An optimized node in this article refers to a node that is configured to handle specific types of workloads, such as compute-intensive, memory-intensive, or storage-purpose tasks. These nodes are fine-tuned to provide the necessary resources and environment to ensure optimal performance for the pods they host.
Official terminology
Taints:
Taints are applied to nodes to repel certain pods, ensuring that only specific pods can be scheduled on those nodes. This helps in maintaining the specialized environment of the node.
Tolerations:
Tolerations are applied to pods, allowing them to be scheduled on nodes with matching taints. This ensures that only the intended pods are placed on the specialized nodes.
Node Affinity:
Node affinity defines rules for pods to prefer or require scheduling on nodes with specific labels. This provides a more flexible and powerful way to control pod placement compared to node selectors.
Case Study Introduction
We will paint up a scenario here.
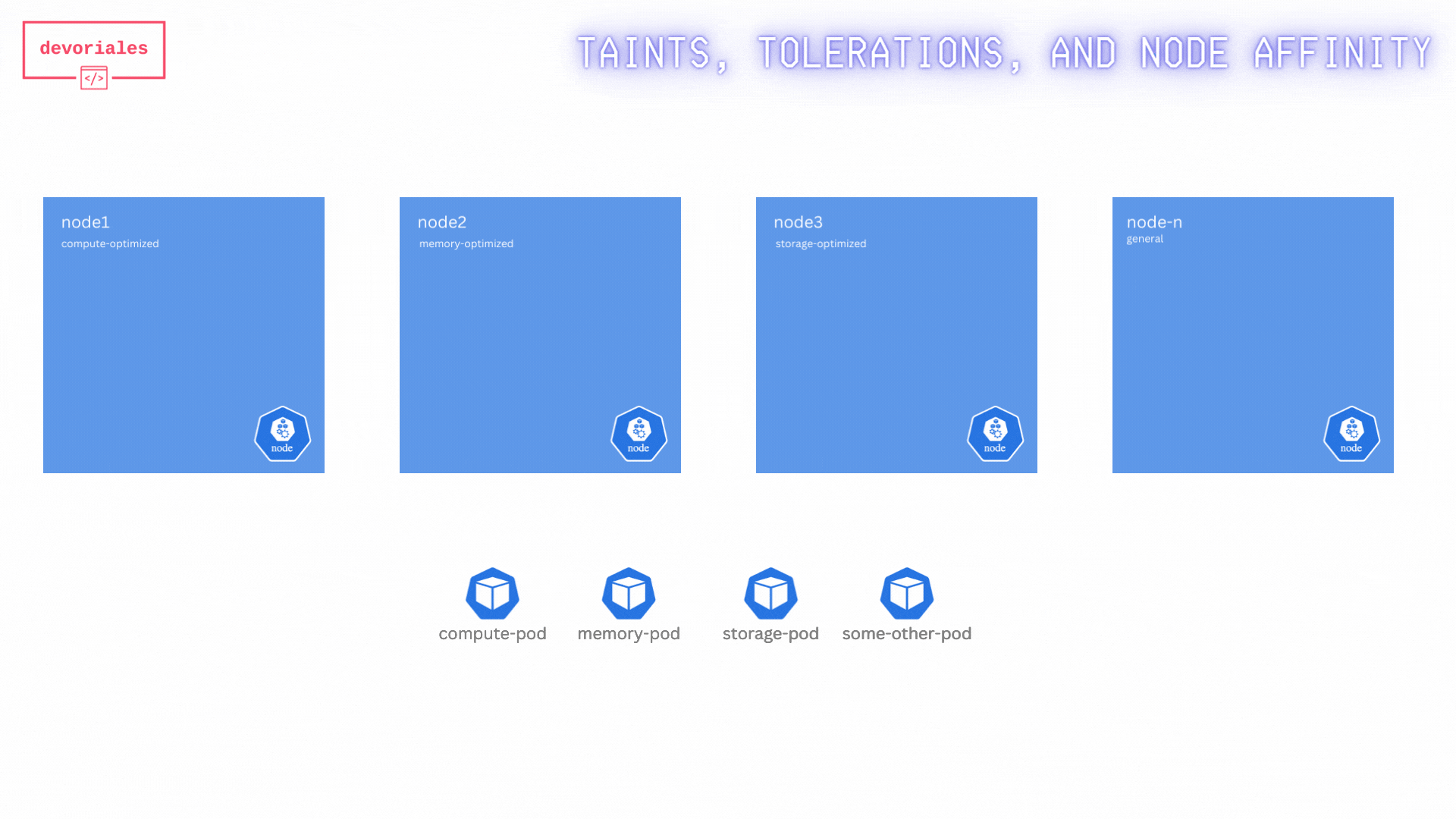
You have a cluster with several nodes dedicated to specific workloads: compute-intensive, memory-intensive, and storage-intensive. In addition, we have some other pods to be scheduled. And there are other nodes too.
node1, node2 and node3 are optimized nodes.
You need to ensure that specific pods are scheduled on these nodes and no other pods are placed on these specialized nodes. These specific pods shall not be placed on other nodes than those that serves the purpose.
We will try to solve this problem by using each method individually and also combine them. The aim here is to find the optimal solution to this challenge and cover the drawbacks.
Attempt 1 - Using Taints and Tolerations
In this first attempt, we will try to solve our challenge by just using the Taints and Tolerations.
Taints and Tolerations Overview
Taints and tolerations are ways in Kubernetes that allow you to control which pods can be scheduled on which nodes. Taints are applied to nodes to repel pods, while tolerations are applied to pods to allow them to be scheduled on nodes with matching taints.
First, we will taint the nodes:
kubectl taint nodes node1 dedicated=compute:NoSchedule
kubectl taint nodes node2 dedicated=memory:NoSchedule
kubectl taint nodes node3 dedicated=storage:NoScheduleThe taint effect determines what happens to pods that cannot tolerate the taint. There are three effects:
- NoSchedule: Pods that cannot tolerate this taint will not be scheduled on the node.
- PreferNoSchedule: The scheduler will try to avoid scheduling pods that cannot tolerate this taint on the node, but it’s not a strict rule.
- NoExecute: If a pod cannot tolerate this taint, it will be evicted from the node if it is already running.
So far, what we have achieved is, no pods will be scheduled on node1, node2 and node3.
Now, we need to add tolerations to the specific workloads.
compute-pod toleration:
apiVersion: v1
kind: Pod
metadata:
name: compute-pod
spec:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "compute"
effect: "NoSchedule"memory pod -toleration:
apiVersion: v1
kind: Pod
metadata:
name: memory-pod
spec:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "memory"
effect: "NoSchedule"storage-pod toleration:
apiVersion: v1
kind: Pod
metadata:
name: storage-pod
spec:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "storage"
effect: "NoSchedule"The pods will be able to be scheduled on each designated node. Great!
Now to the problem. Look at the diagram. Storage pod is placed on another node, not the storage optimized node that we wanted.
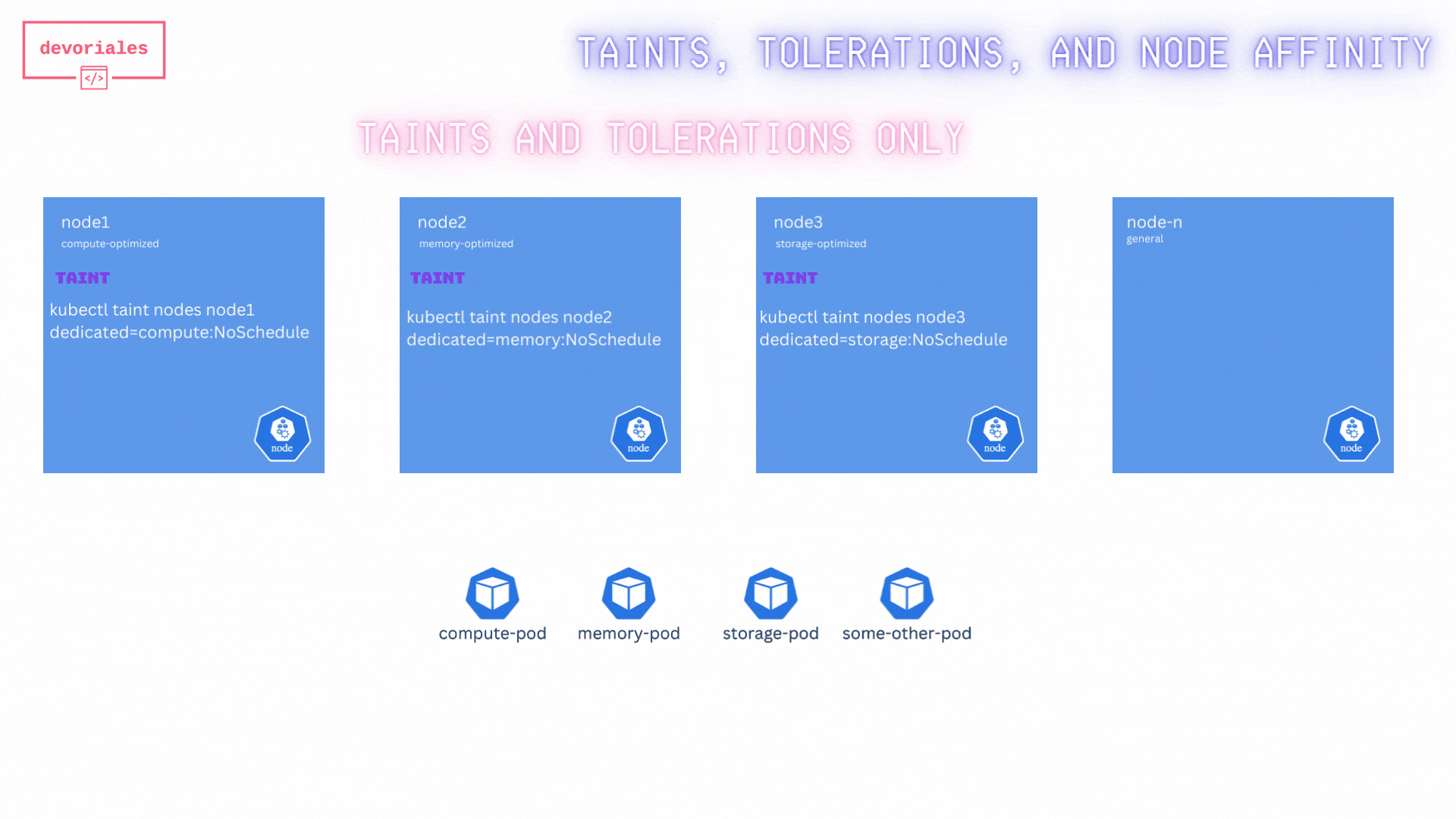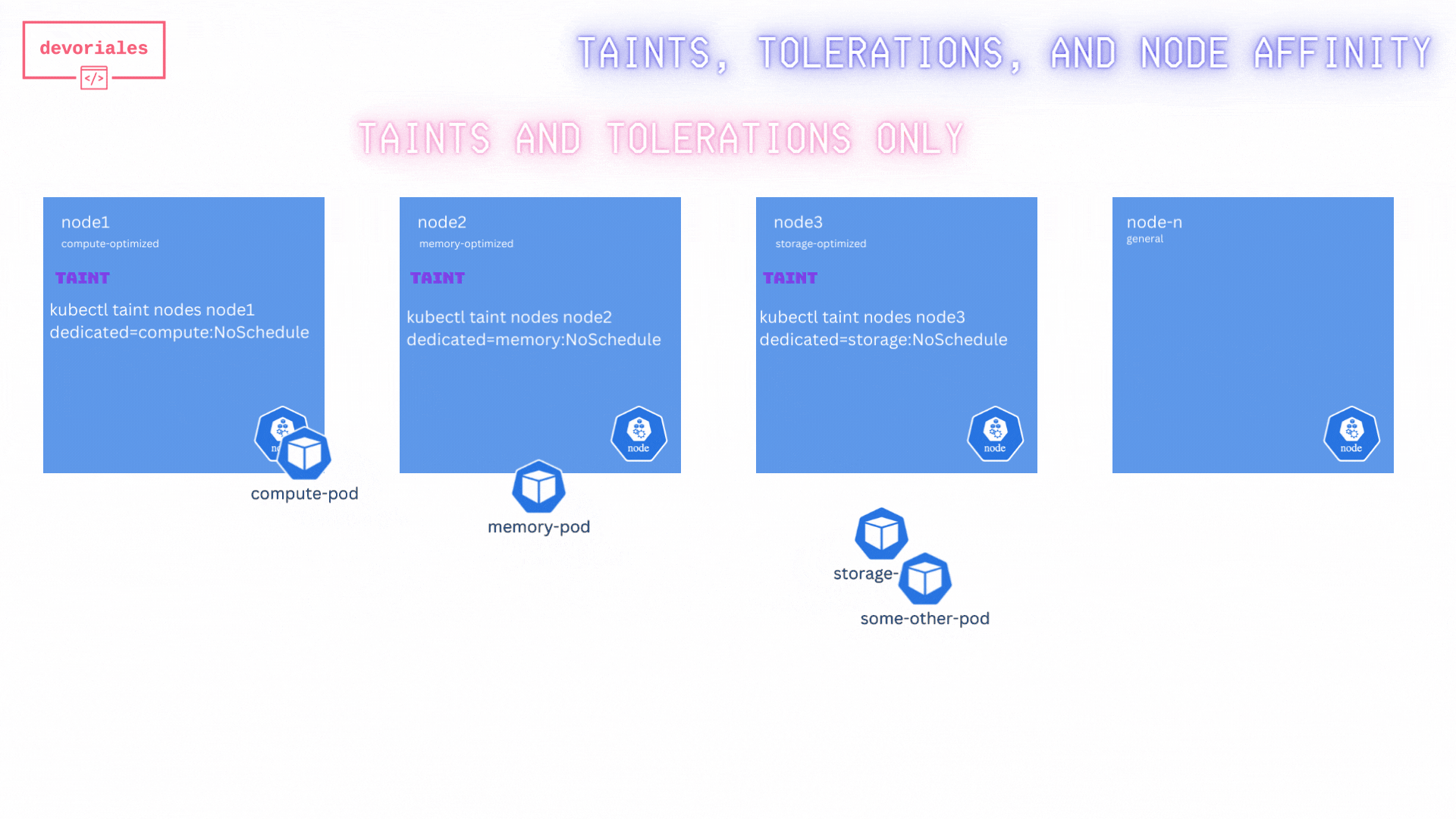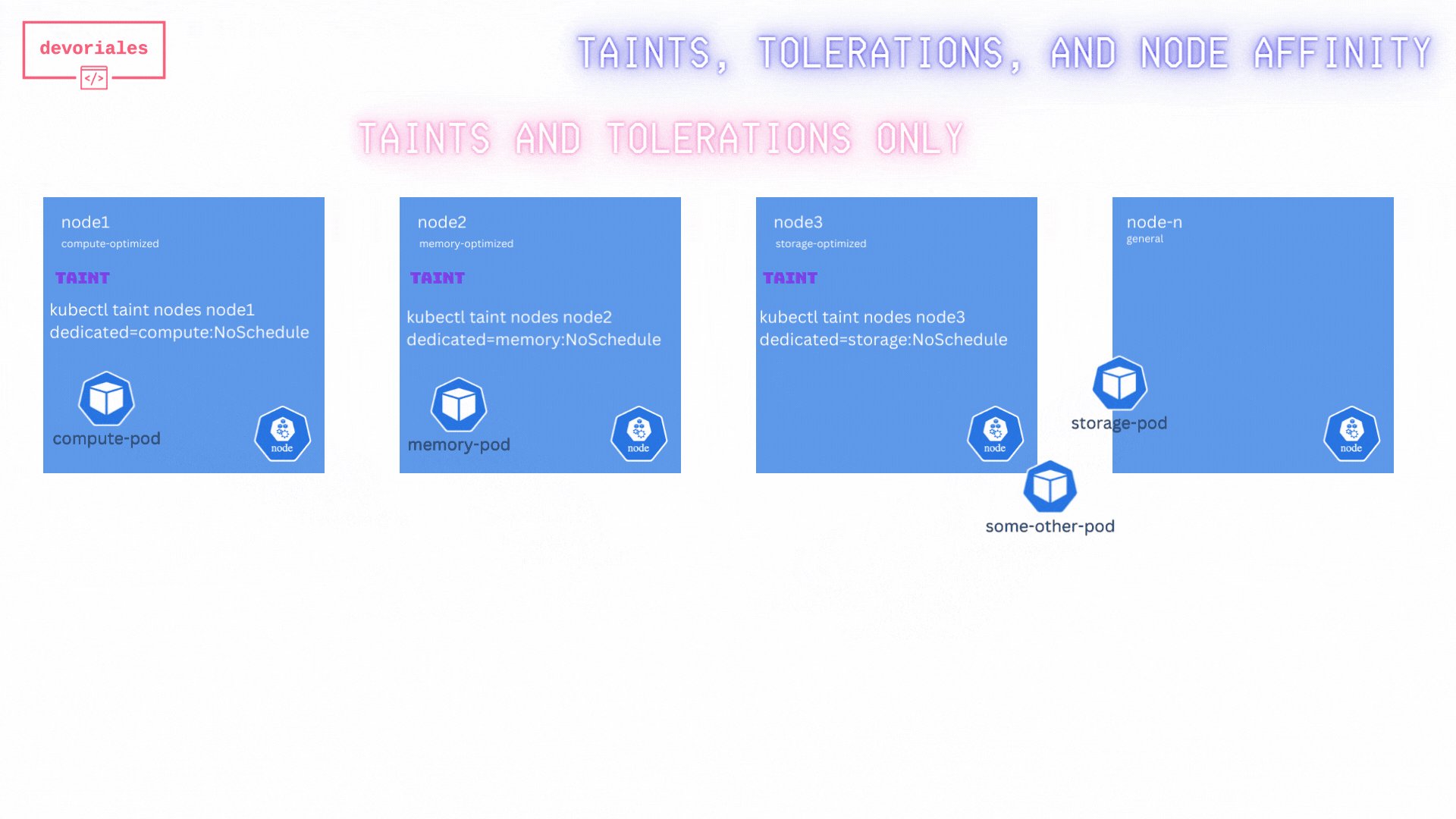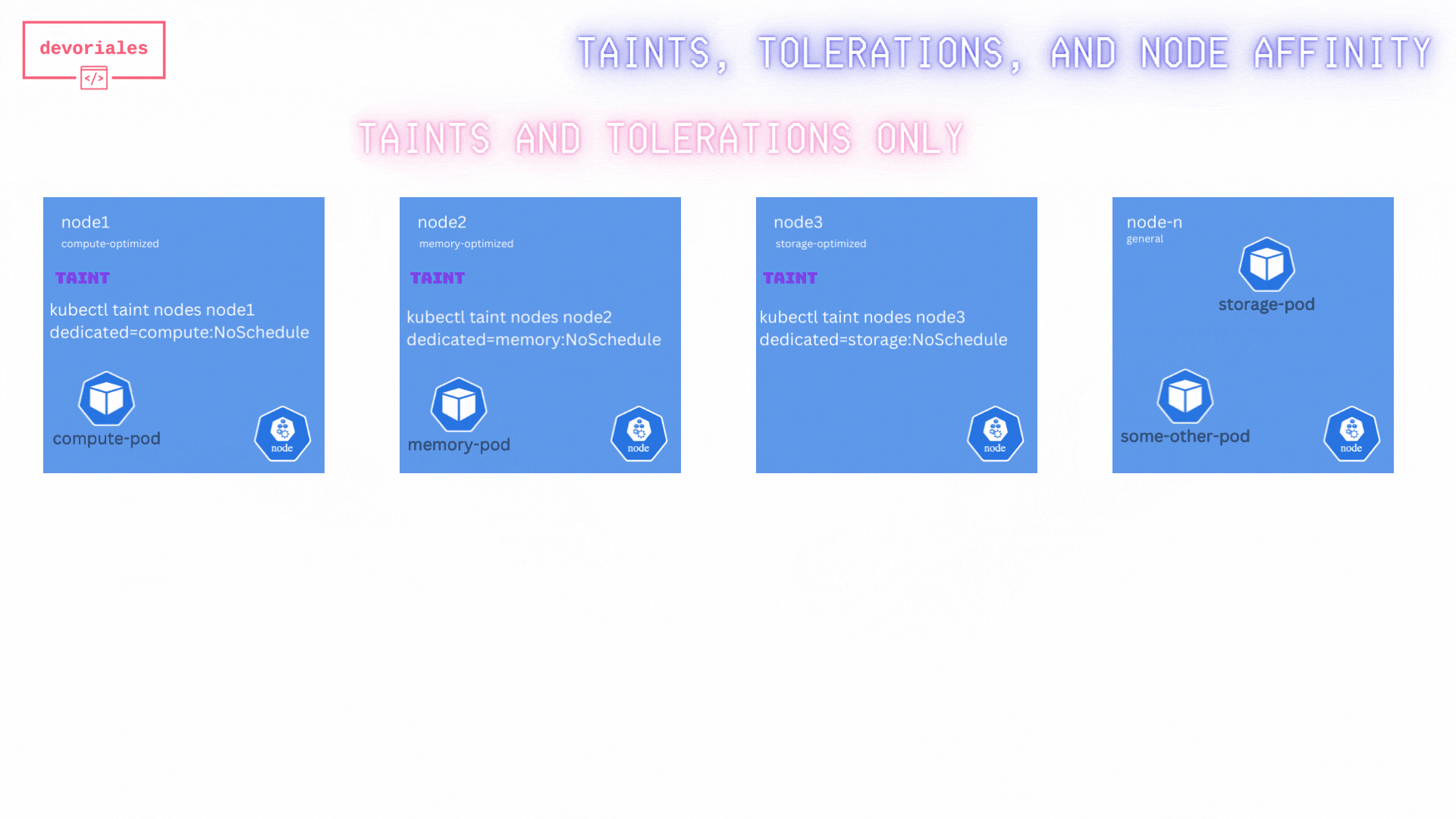
While this ensures that only specific pods can be scheduled on the tainted nodes, it doesn’t prevent these pods from being scheduled on other nodes without taints.
❌ Unfortunately, the taints and tolerations didn’t solve the challenge. The special pods we have with the tolerations can still be placed on other nodes than the ones we expect.
Attempt 2 - Using Node Affinity
Node affinity is a set of rules used by the Kubernetes scheduler to determine which nodes a pod can be scheduled on, based on the labels of the nodes. It’s more flexible than Node Selector, allowing for complex expressions.
Instead of tainting the nodes, we'll label them as follows:
kubectl label nodes node1 dedicated=compute
kubectl label nodes node2 dedicated=memory
kubectl label nodes node3 dedicated=storage
❗Node affinity offers greater flexibility and control over pod scheduling compared to nodeSelector. While nodeSelector only supports simple key-value matching, node affinity allows for complex rules using operators like In, NotIn, and Exists. Additionally, node affinity supports both mandatory (hard) and preferred (soft) constraints, enabling more nuanced and efficient scheduling decisions. This results in better resource utilization and optimized workload management within a Kubernetes cluster.
Example nodeSelector configuration:
apiVersion: v1
kind: Pod
metadata:
name: ssd-pod
spec:
nodeSelector:
disktype: ssdLet's now add a nodeAffinity rule to the pods.
compute-pod - affinity rule:
apiVersion: v1
kind: Pod
metadata:
name: compute-pod
spec:
containers:
- name: compute-container
image: compute-container-image
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: dedicated
operator: In
values:
- computememory-pod affinity rule:
apiVersion: v1
kind: Pod
metadata:
name: memory-pod
spec:
containers:
- name: memory-container
image: memory-container-image
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: dedicated
operator: In
values:
- memory
storage-pod affinity rule:
apiVersion: v1
kind: Pod
metadata:
name: storage-pod
spec:
containers:
- name: storage-container
image: storage-container-image
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: dedicated
operator: In
values:
- storage
There are two types of node affinity constraints:
- requiredDuringSchedulingIgnoredDuringExecution: The scheduler must find a node that satisfies this rule; otherwise, it cannot schedule the Pod. Does not affect running pods.
- preferredDuringSchedulingIgnoredDuringExecution: The scheduler attempts to find a node that satisfies this rule. If no such node is available, the scheduler will still schedule the Pod on another node. With other words, no guarantee that the pod will end up on the node we want.
These configurations ensure that each type of pod can be scheduled on the appropriate node based on node labels, without using tolerations:
- Compute Pods: Scheduled only on nodes labeled with
dedicated=compute. - Memory Pods: Scheduled only on nodes labeled with
dedicated=memory. - Storage Pods: Scheduled only on nodes labeled with
dedicated=storage.
This approach places each pod on the nodes best suited for its specific resource requirements.
This is great you might think, this kind of solves the problem.
Look at the diagram and inspect what's happening:
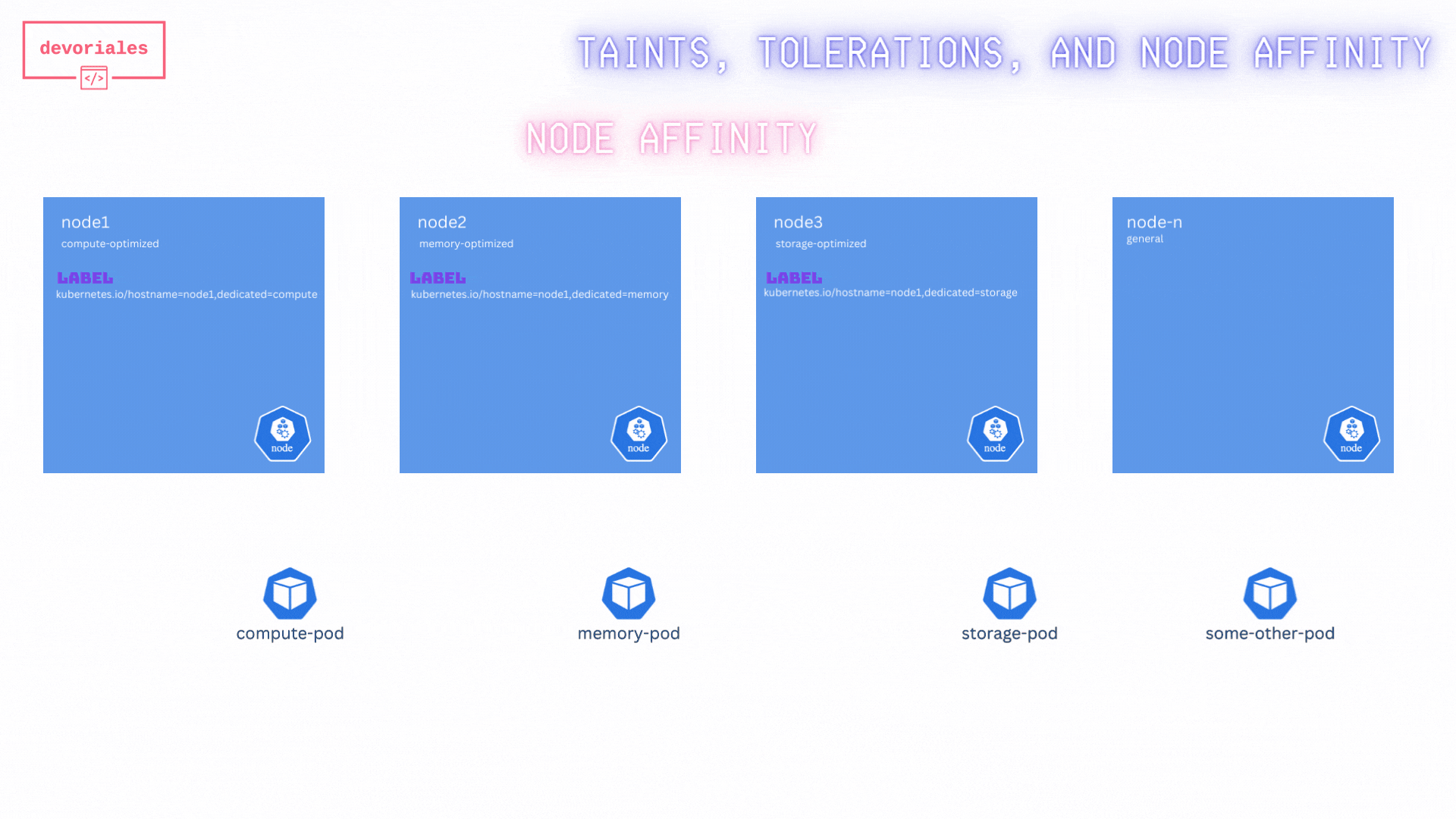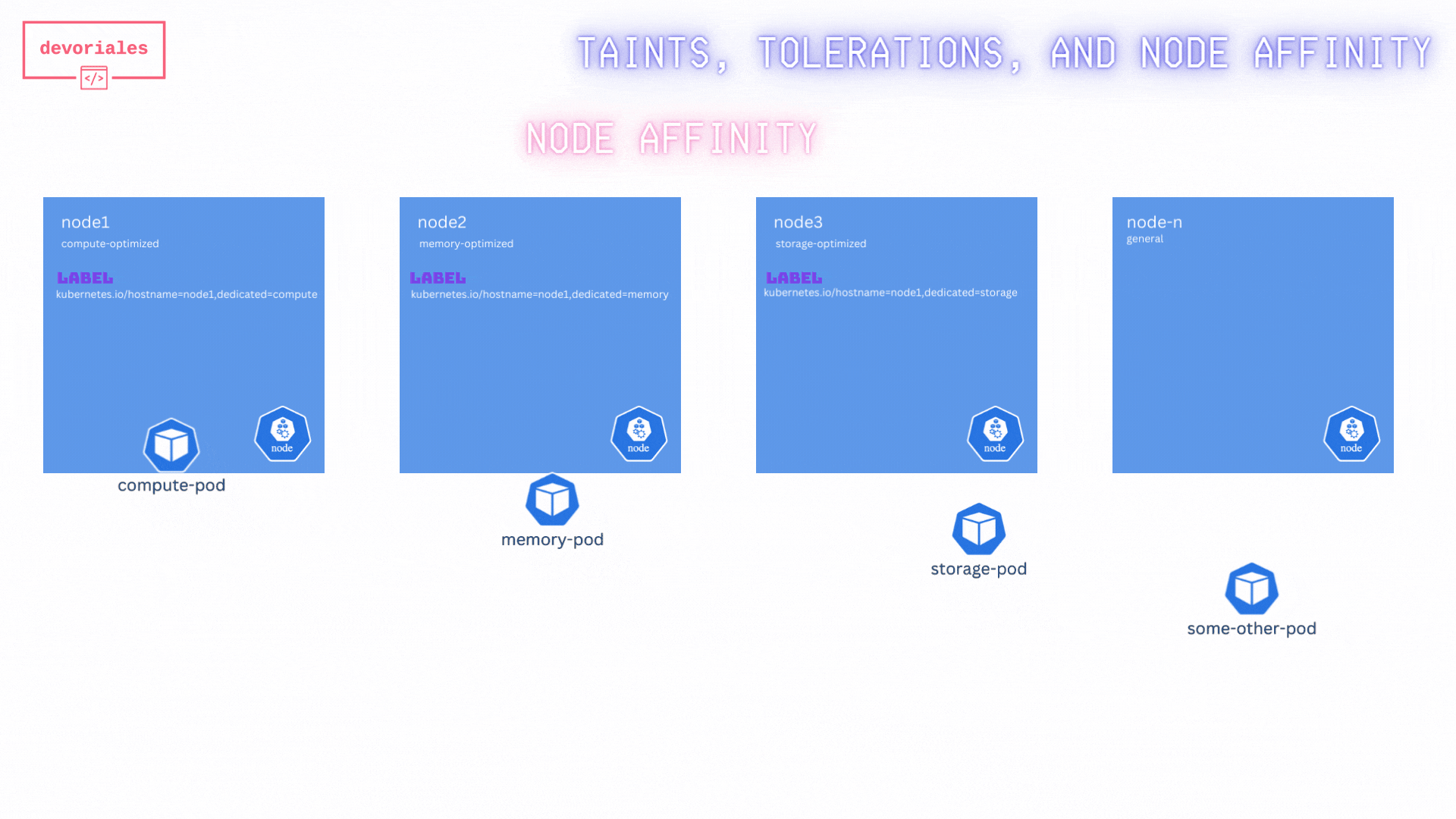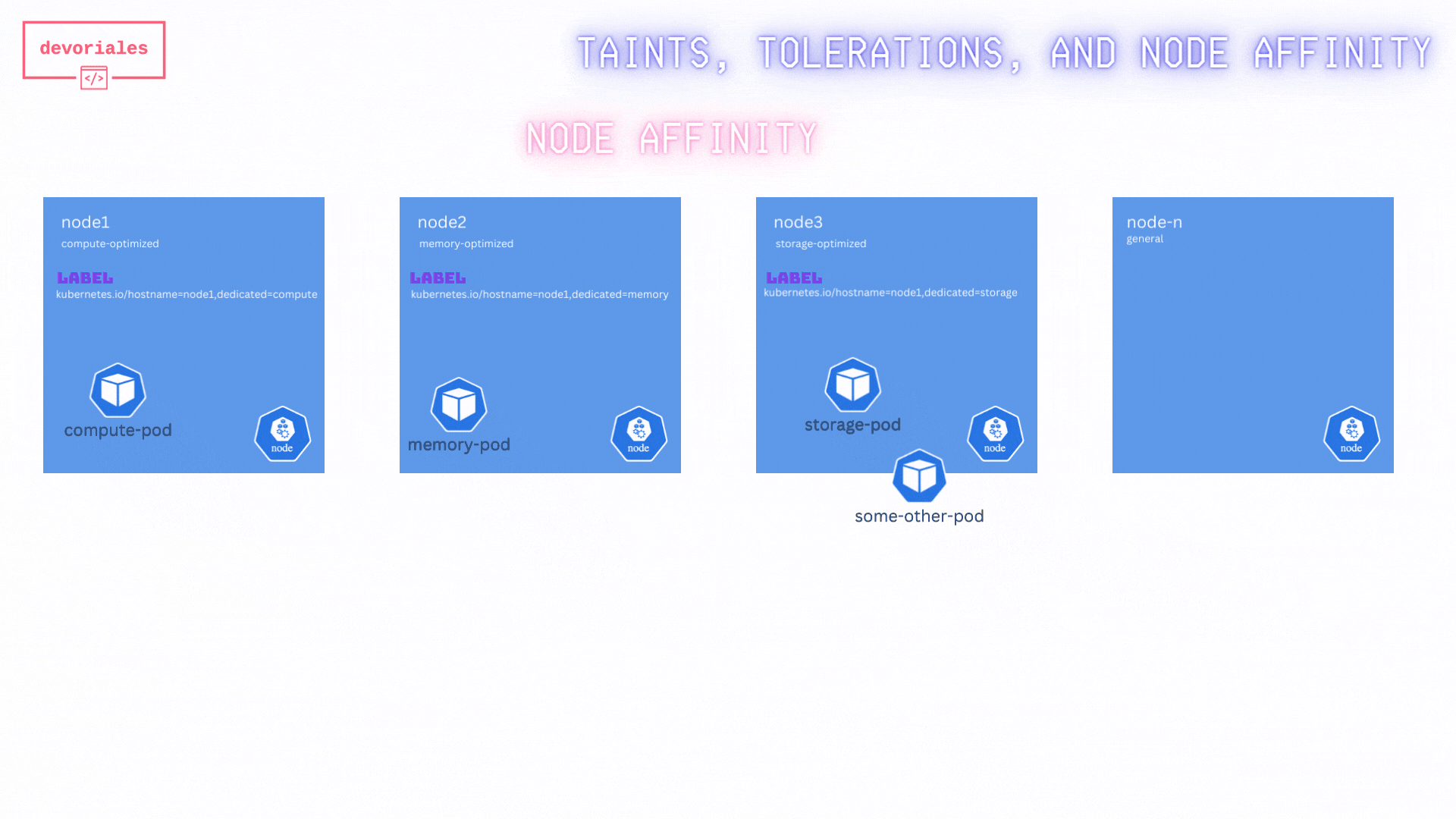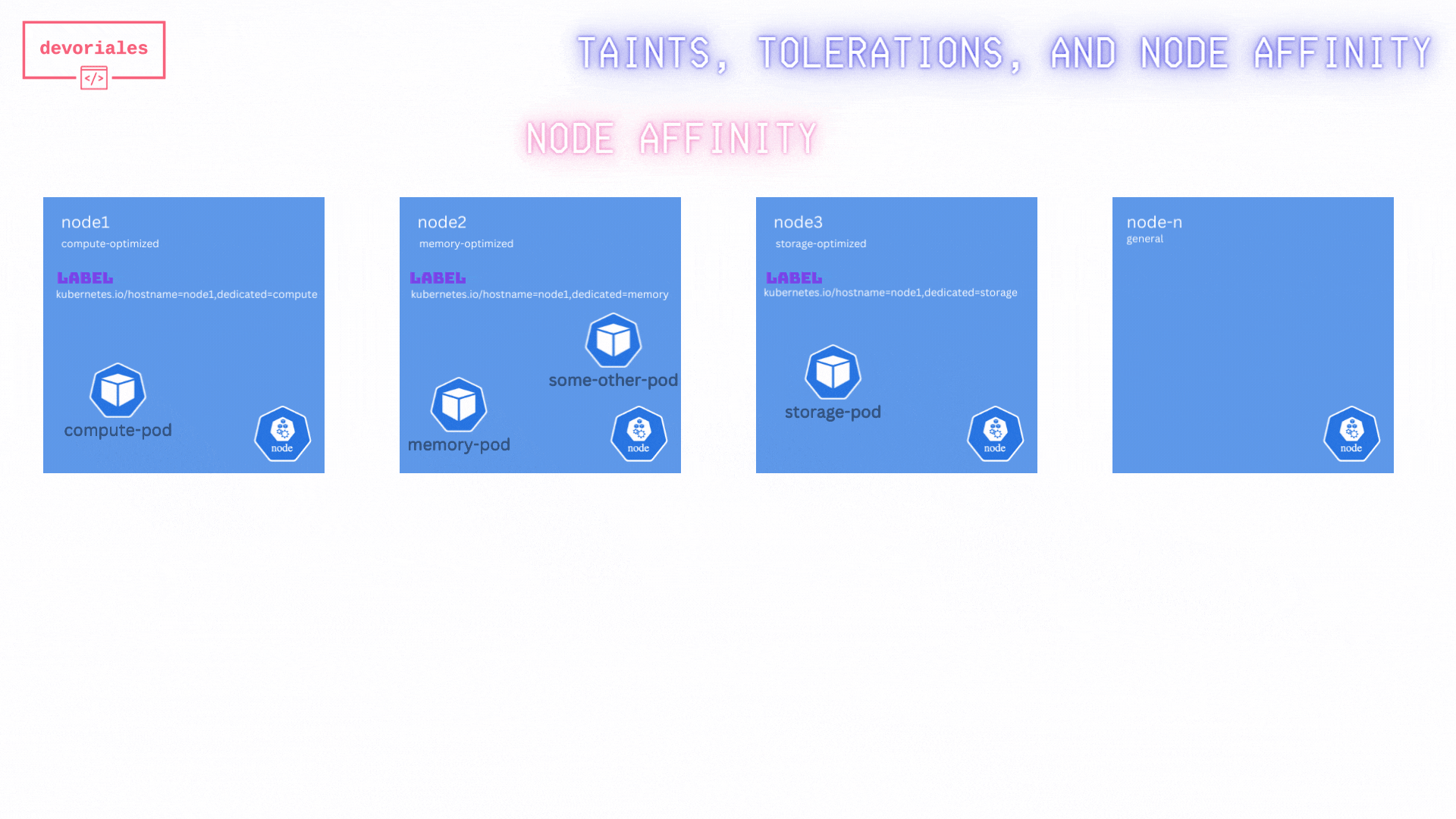 Unfortunatelly, the "some-other-pod" is getting scheduled on node2, not really what we expected.
Unfortunatelly, the "some-other-pod" is getting scheduled on node2, not really what we expected.
The reason is, while this method ensures that specific pods are directed to the appropriate nodes, it does not prevent other pods from being scheduled on these specialized nodes. As a result, it does not fully solve the problem of exclusive node usage for specific workloads.
❌ Just using node affinity rule didn't solve our challenge.
Attempt 3 - Combined Use of Taints & Tolerations, and Node Affinity
In this last attempt, we will combine everything we have to solve our challenge.
Label the nodes
To be able to use node affinity, we need to label our nodes:
kubectl label nodes node1 dedicated=compute
kubectl label nodes node2 dedicated=memory
kubectl label nodes node3 dedicated=storage
Add Taint to the nodes
Since we also use the taints and tolerations, we'll taint the nodes:
kubectl taint nodes node1 dedicated=compute:NoSchedule
kubectl taint nodes node2 dedicated=memory:NoSchedule
kubectl taint nodes node3 dedicated=storage:NoSchedulePods without the necessary tolerations will not be scheduled on these nodes.
Add tolerations to the pods
To tolerate the taints, the pods need to have tolerations.
compute-pod toleration config:
apiVersion: v1
kind: Pod
metadata:
name: compute-pod
spec:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "compute"
effect: "NoSchedule"memory-pod toleration config:
apiVersion: v1
kind: Pod
metadata:
name: memory-pod
spec:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "memory"
effect: "NoSchedule"storage-pod toleration config:
apiVersion: v1
kind: Pod
metadata:
name: storage-pod
spec:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "storage"
effect: "NoSchedule"Add node affinity rules
Lastly, we will add affinity rules to our pods. We will keep the toleration from the previous step.
compute-pod:
apiVersion: v1
kind: Pod
metadata:
name: compute-pod
spec:
containers:
- name: compute-container
image: compute-container-image
tolerations:
- key: "dedicated"
operator: "Equal"
value: "compute"
effect: "NoSchedule"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: dedicated
operator: In
values:
- computememory-pod:
apiVersion: v1
kind: Pod
metadata:
name: memory-pod
spec:
containers:
- name: memory-container
image: memory-container-image
tolerations:
- key: "dedicated"
operator: "Equal"
value: "memory"
effect: "NoSchedule"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: dedicated
operator: In
values:
- memorystorage-pod:
apiVersion: v1
kind: Pod
metadata:
name: storage-pod
spec:
containers:
- name: storage-container
image: storage-container-image
tolerations:
- key: "dedicated"
operator: "Equal"
value: "storage"
effect: "NoSchedule"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: dedicated
operator: In
values:
- storageWhat have we achieved here?
When combining all three techniques here, we actually achieve what we want.
Inspect the diagram below:
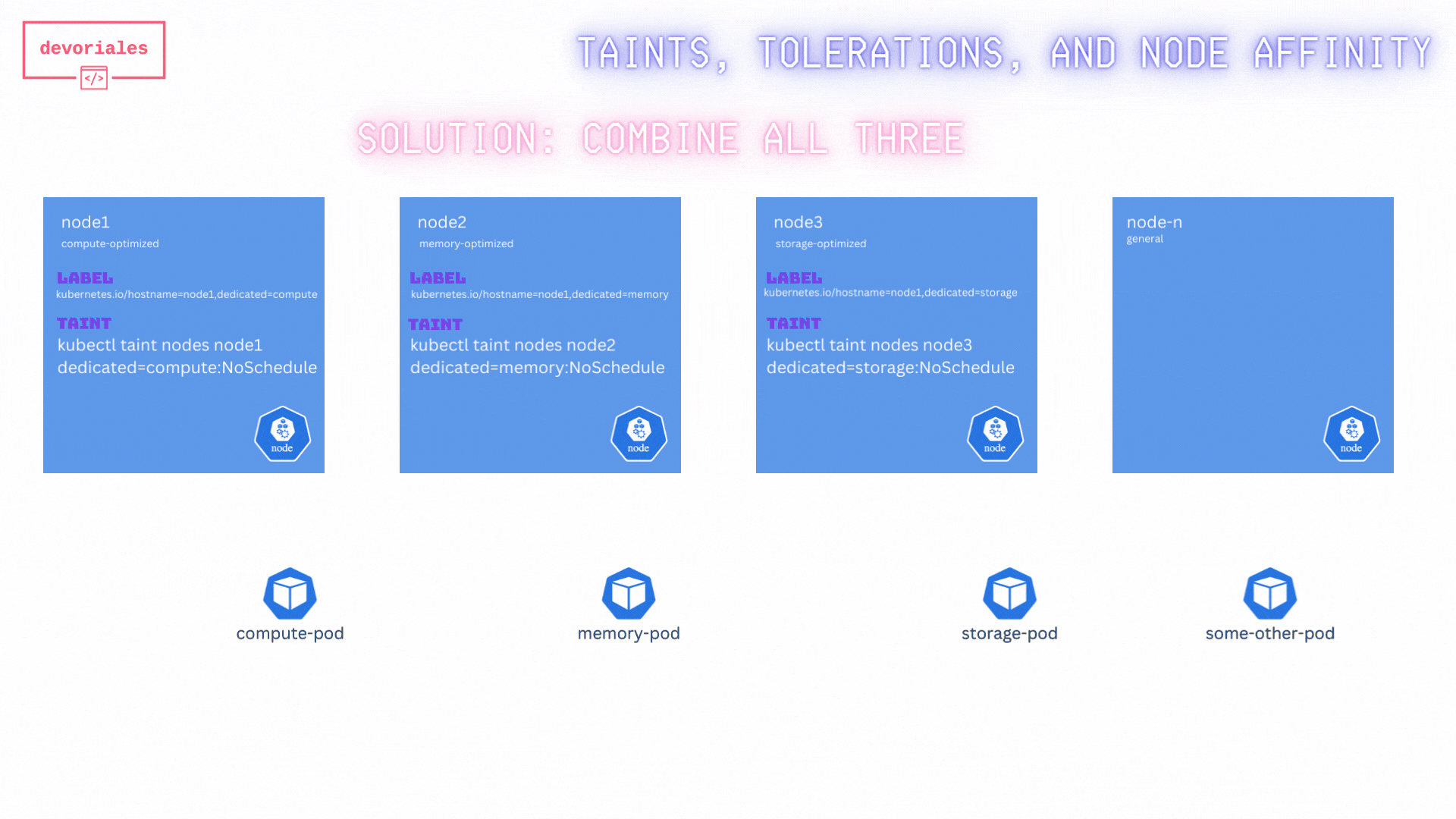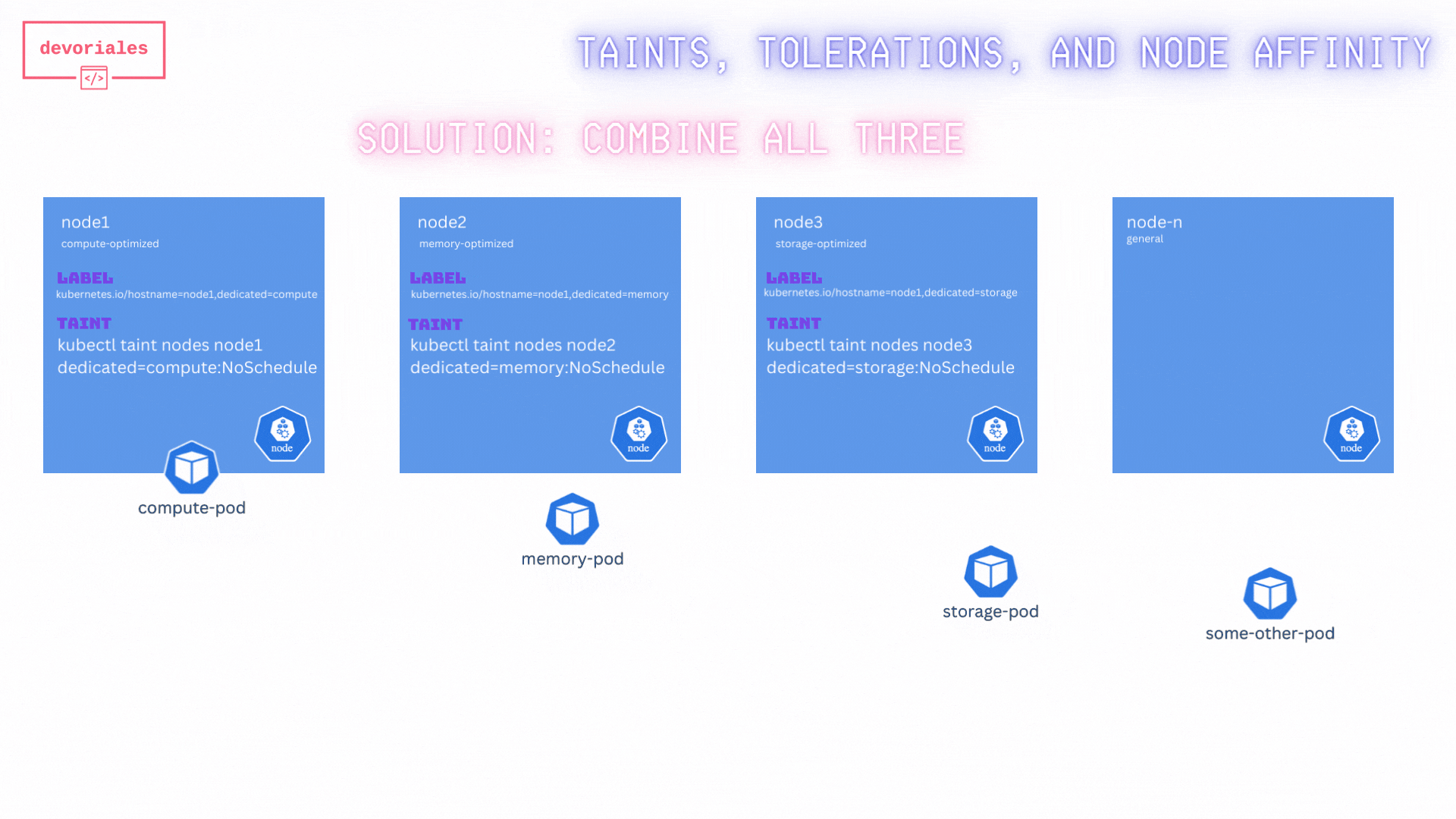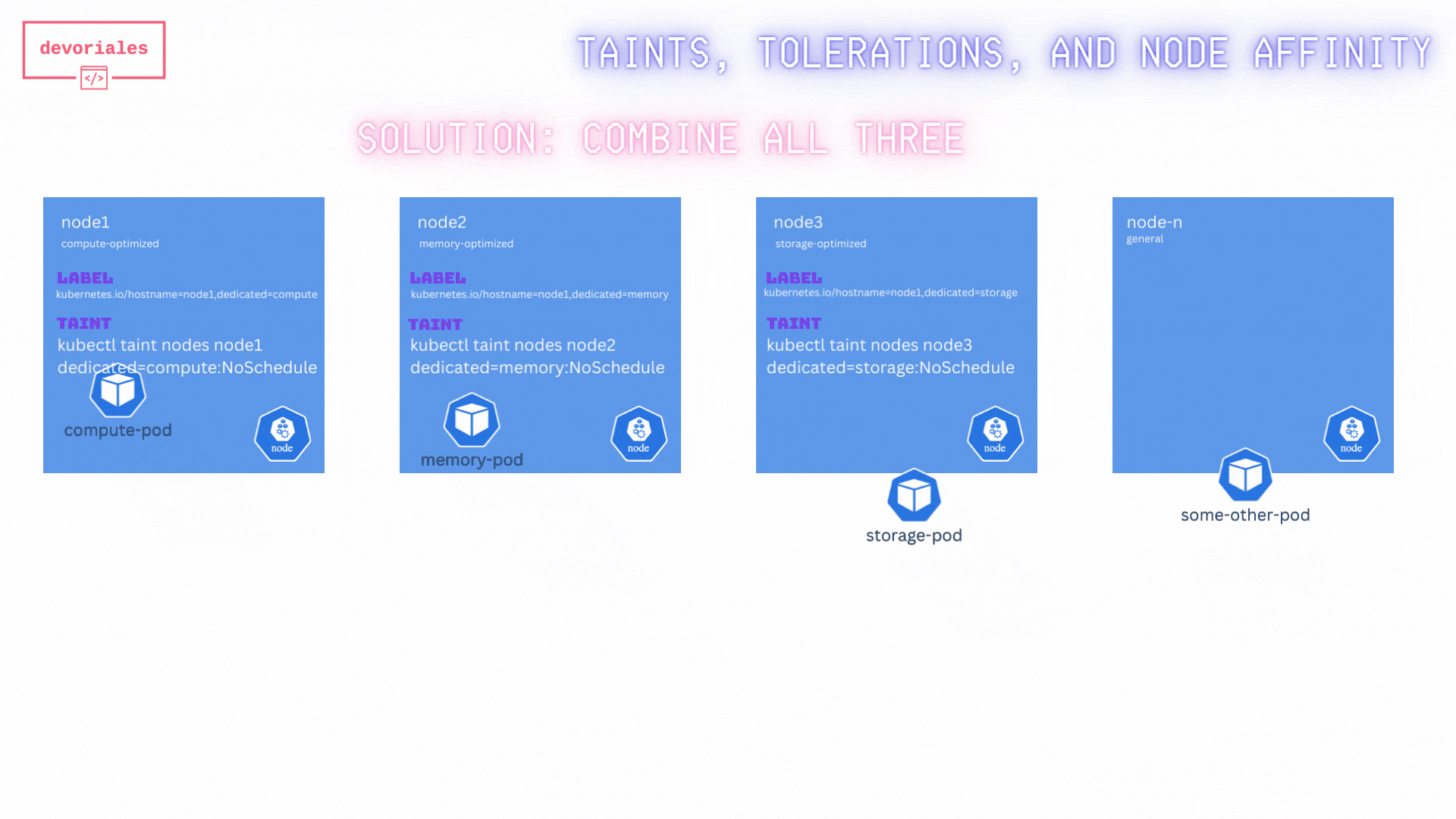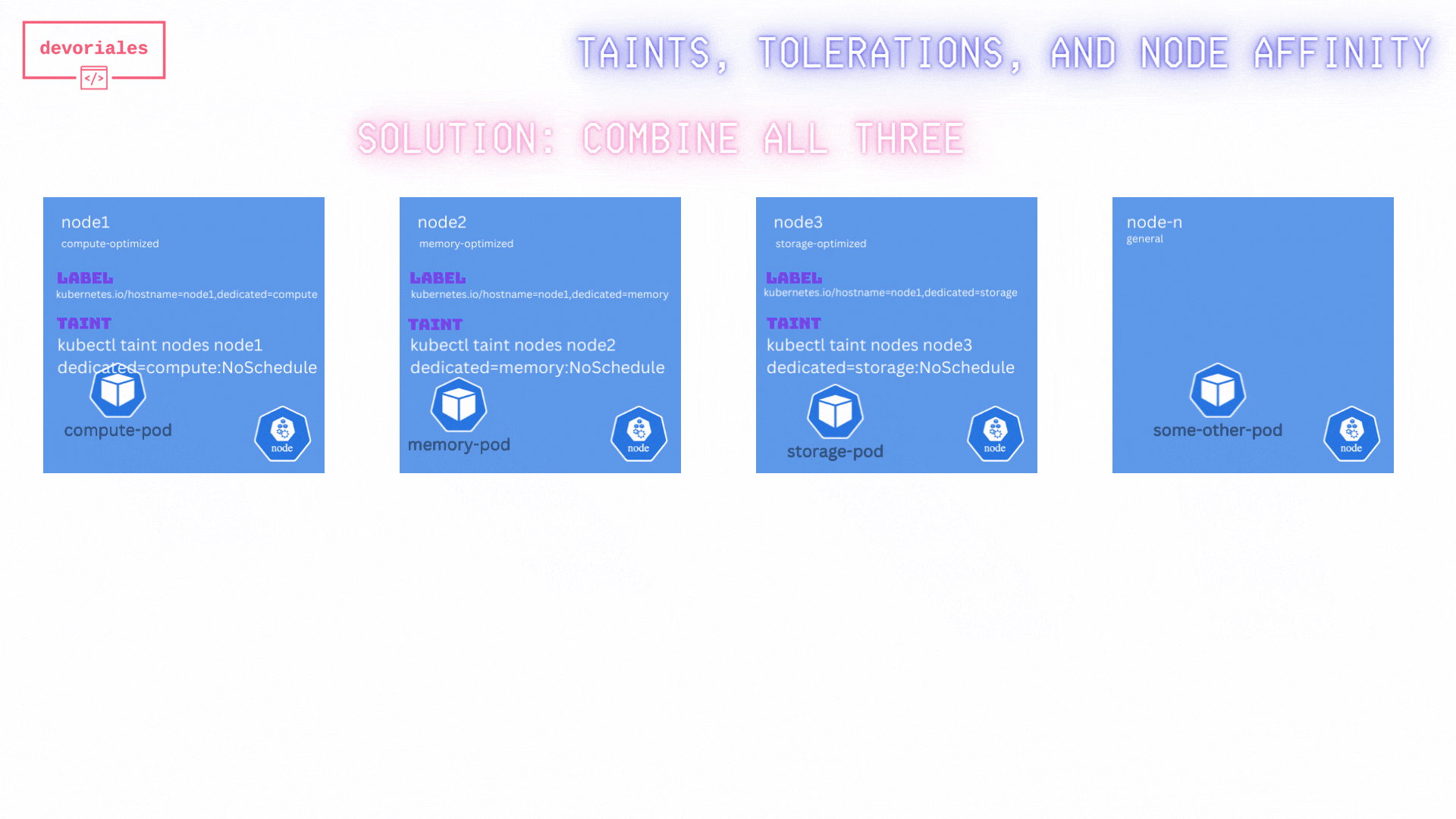
By combining taints, tolerations, and node affinity, we've ensure that:
- Only the specified pods are scheduled on the optimized nodes.
- No other pods are scheduled on these nodes.
- The scheduler is guided to place the pods on the most suitable nodes based on their requirements.
✅ Great, that’s exactly what we wanted. Combining taints, tolerations, and node affinity rules ensured that the pods were scheduled correctly.
Conclusion
Combining taints, tolerations, and node affinity in Kubernetes provides control over pod placement, ensuring that workloads are distributed based on the requirements of each pod and node. With the covered implementation, we can ensure that critical applications receive the resources they need.