
Retrieval Augmented Generation (RAG) Explained for Beginners Like Me
God dammit, there is RAG here RAG there lately, and I didn't get it
Perhaps you're confused as I am, or at least was until a few days back 🤣
This post is not for those working in the ML and AI fields, but you're absolutely welcome to comment and suggest improvements.
So what is it? First of all, it stands for Retrieval-Augmented Generation 😱
It's a technique in natural language processing (NLP) that enhances the capabilities of AI models by combining the strengths of retrieval systems and generative models. Here's a detailed, hopefully beginner-friendly explanation of RAG (I'm a beginner in this field so don't listen to me)
Here is a simplified RAG model:
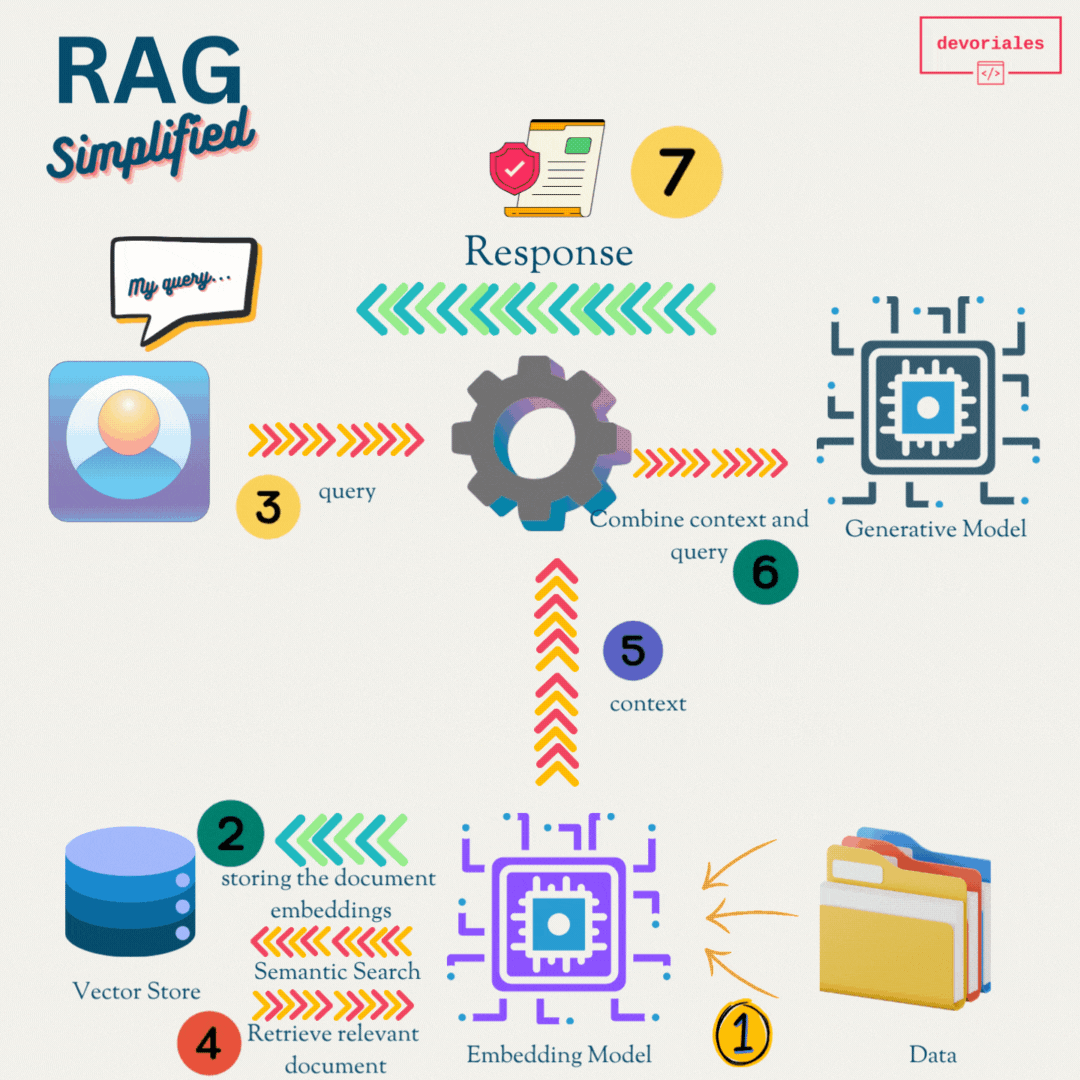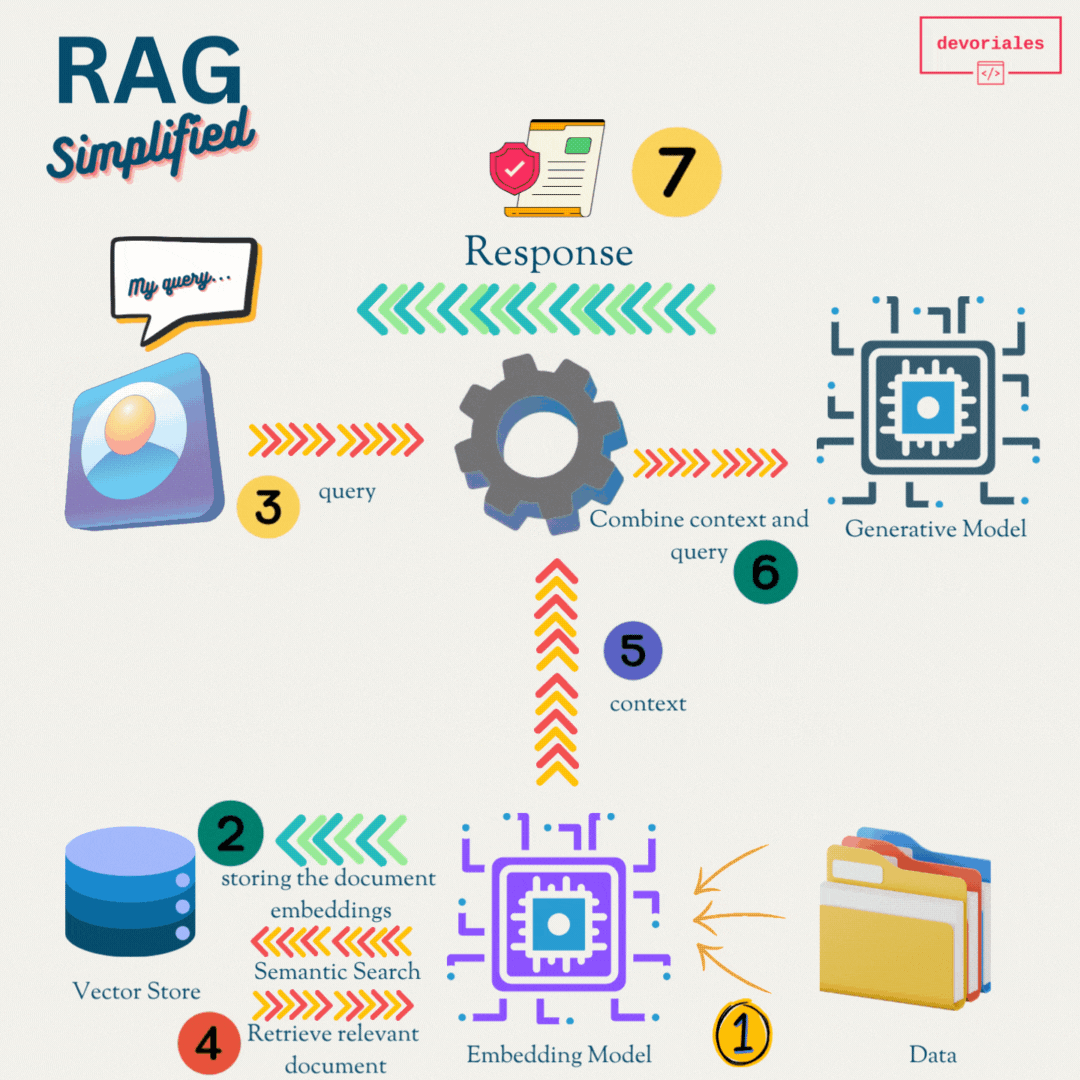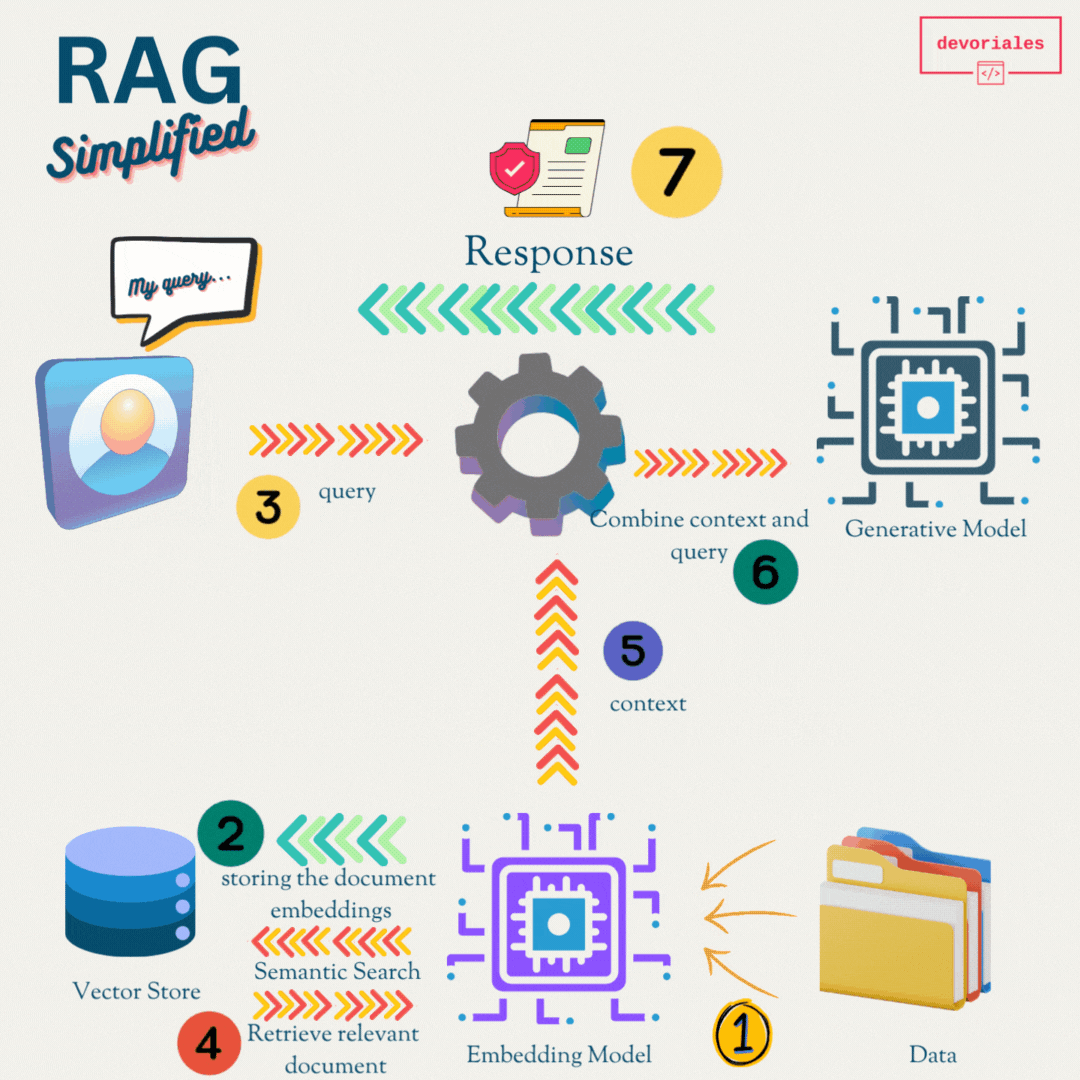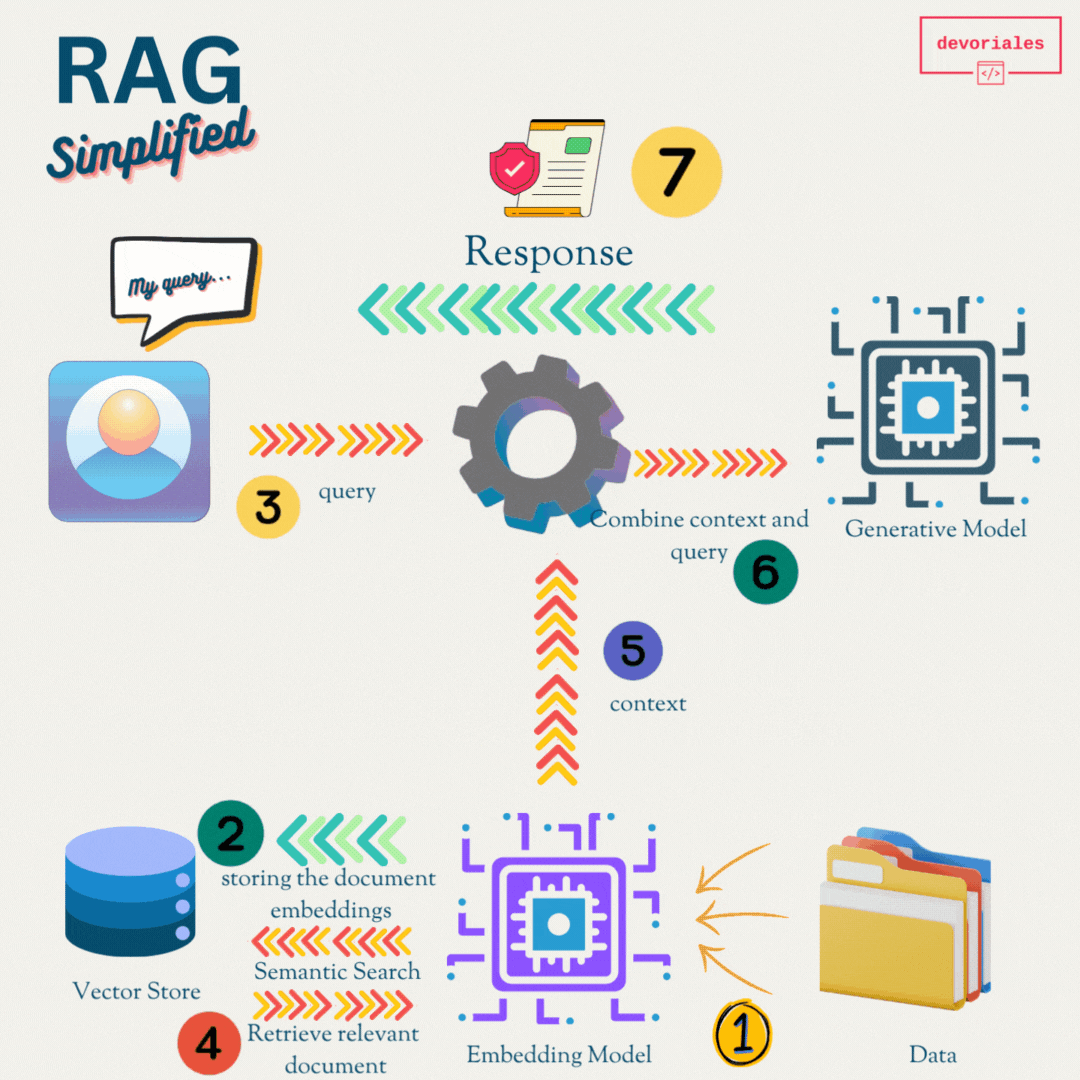
Retrieval Systems
Function: These systems are designed to fetch relevant information from a vast dataset or knowledge base, functioning similarly to advanced search engines.
Example: When you ask, "What is Kubernetes?", a retrieval system searches through a database and returns documents or snippets explaining Kubernetes.
Generative Models
These models generate text based on the input they receive, creating coherent and contextually relevant sentences, paragraphs, or even long articles.
When you ask, "Write a summary of Kubernetes," a generative model produces a text summarizing Kubernetes based on its training data.
How RAG Works
- Retrieval: When a question or query is posed, the retrieval component searches a large database or knowledge base to find relevant information.
- Augmentation: The retrieved information is then passed to the generative model.
- Generation: The generative model uses the retrieved information to produce a coherent and contextually accurate response.
So why two different models?
- Improved Accuracy: By combining retrieval with generation, RAG systems provide more accurate and informative answers. The retrieval step ensures access to the most relevant information, which the generative model uses to construct a detailed response.
- Context-Aware Responses: Generative models in RAG produce more context-aware and nuanced answers, guided by the precise information retrieved from a large dataset.
RAG models handle a wide range of queries, from simple factual questions to more complex, nuanced stuff.
Project Kube-know
Let's build something simple but powerful in Python to demystify RAG. We'll use a small dataset and two pre-trained models: one for retrieval and one for generation. Our small system will combine a retrieval component, which fetches relevant information from a dataset, and a generative component, which generates coherent and contextually appropriate text based on the retrieved information. This project will help us understand the fundamental principles of RAG and see it in action.
❗We'll use generative model, GPT-2, but why? The GPT-2 model was chosen because it doesn't require an API token. You can modify the code to use more advanced models if desired, but the current setup is intended to help us understand the concept.
First, we will install some libraries that are used:
pip install sentence-transformers transformers
Let's create a small dataset of text that our retrieval system will search through. I've packed the code with silly comments to better understand.
# rug.py
# devoriales.com, 20240624
from sentence_transformers import SentenceTransformer, util
from transformers import pipeline
# Load pre-trained models
'''
We use two different models to perform the two tasks: retrieval and generation. That's how the RAG model works.
The retrieval model is a SentenceTransformer model that encodes the documents and queries into embeddings.
The generation model is a GPT-2 model that generates the response given the retrieved information and the query.
'''
# The retrieval model encodes documents and queries into embeddings.
retriever = SentenceTransformer('paraphrase-MiniLM-L6-v2') # Efficient retrieval model
# The generation model generates responses based on the context provided by the retrieved information.
generator = pipeline('text-generation', model='gpt2-medium') # Powerful generative model
# Example dataset
# This small dataset contains documents about Kubernetes, Docker, and machine learning.
documents = [
"Kubernetes is an open-source container-orchestration system for automating computer application deployment, scaling, and management.",
"Docker is a set of platform as a service products that use OS-level virtualization to deliver software in packages called containers.",
"Machine learning is the study of computer algorithms that improve automatically through experience.",
]
# Embed the documents
# Here we use the retrieval model to encode the documents into embeddings for efficient similarity search.
document_embeddings = retriever.encode(documents, convert_to_tensor=True)
def retrieve(query, k=1):
# Embed the query
# The query is encoded into an embedding using the retrieval model.
query_embedding = retriever.encode(query, convert_to_tensor=True)
# Retrieve the most similar document
# We use semantic search to find the most relevant document from the encoded dataset.
hits = util.semantic_search(query_embedding, document_embeddings, top_k=k)
# Get the most relevant document
# The most relevant document is identified based on the highest similarity score.
most_relevant_doc = documents[hits[0][0]['corpus_id']]
return most_relevant_doc
def generate_response(retrieved_info, query):
# Combine the retrieved info and the query
# The retrieved information and the query are combined to form the input for the generative model.
input_text = f"Context: {retrieved_info}\n\nQuestion: {query}\nAnswer: Kubernetes is"
# Generate the response with specific length constraints
# The generative model generates a response based on the combined input text.
response = generator(
input_text,
max_length=150, # Maximum length of the generated response
min_length=50, # Minimum length of the generated response
num_return_sequences=1, # Number of responses to generate
no_repeat_ngram_size=2, # Prevents repeating sequences of words
early_stopping=True, # Stops early when the model is confident
temperature=0.5, # Controls randomness: lower value = more deterministic
top_k=50, # Considers the top_k most likely next words
top_p=0.9, # Top-p (nucleus) sampling, considers the cumulative probability
num_beams=5, # Beam search to improve generation quality
truncation=True, # Truncate inputs to fit max length
pad_token_id=generator.tokenizer.eos_token_id # Pad token for the model to know when to stop.
)
return response[0]['generated_text']
# Example usage
query = input("Enter your question: ")
retrieved_info = retrieve(query)
response = generate_response(retrieved_info, query)
print("Query:", query, '<<<< This is the prompt we provide')
print("Retrieved Information:", retrieved_info, '<<<< This is the retriever response')
print("Response:", response, '<<<< This is coming from the generative model model')
Here comes an autogenerated diagram out of my code to visually show the steps performed:
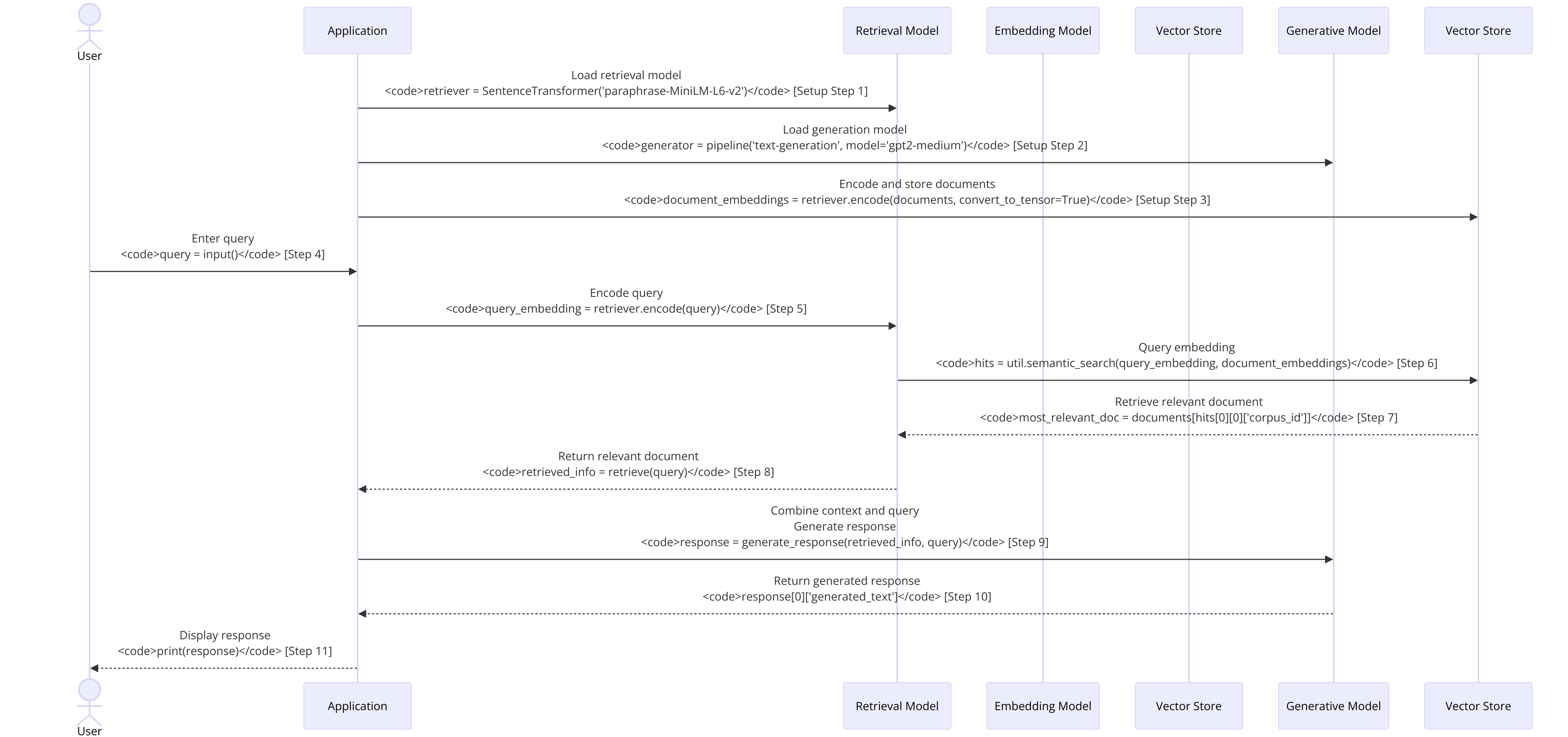
Some clarifications:
transformers: For loading and using pre-trained models like GPT-2 for text generationSentenceTransformer ('paraphrase-MiniLM-L6-v2'): To encode documents and queries into dense vector embeddings for efficient similarity search.
Time to put it on test:
python rag.pyYou will be asked to ask the question:
Enter your question: What is Kubernetes?Outputs:
Query: What is Kubernetes? <<<< This is the prompt we provide
Retrieved Information: Kubernetes is an open-source container-orchestration system for automating computer application deployment, scaling, and management. <<<< This is the retriever response
Response: Context: Kubernetes is an open-source container-orchestration system for automating computer application deployment, scaling, and management.
Question: What is Kubernetes?
Answer: Kubernetes is a distributed, fault-tolerant, multi-tenant container orchestration platform. It is built on top of Docker, the open source container management system, which is used by many of the world's largest enterprises, including Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure, Rackspace, Red Hat Enterprise Linux (RHEL), and many others. The platform is designed to be as easy to use as possible for developers and users, while providing a robust, scalable, <<<< This is coming from the generative model modelFantastic!
Again, the following happened:
- Load Pre-trained Models: We load and initialize the models necessary for the RAG system.
- Initialize Retrieval Model: The
SentenceTransformermodel is loaded to encode documents and queries into embeddings. - Initialize Generative Model: The GPT-2 model is loaded for generating responses.
- Create Dataset: A small example dataset containing documents on Kubernetes, Docker, and machine learning is defined.
- Embed Documents: The dataset documents are encoded into embeddings using the retrieval model.
- Embed Query: When a user inputs a query, it is encoded into an embedding.
- Semantic Search: The query embedding is used to perform a semantic search on the document embeddings to find the most relevant document.
- Retrieve Document: The document with the highest similarity score is retrieved.
- Combine Query and Context: The retrieved document is combined with the original query to form the input for the generative model.
- Generate Response: The combined input is fed into the GPT-2 model to generate a response.
- Output: The response is printed as the final answer to the user's query.
Wrapping Up
In this tutorial, we've explored Retrieval-Augmented Generation (RAG), a powerful technique in natural language processing (NLP) that enhances AI model capabilities by combining retrieval systems and generative models.
RAG works by retrieving relevant information from a large database or knowledge base and then using that information to generate a coherent and contextually accurate response. By combining the precision of retrieval systems with the creativity of generative models, RAG provides more accurate and informative answers.
In our project, we built a simple Python application using a small dataset and two pre-trained models: a SentenceTransformer for retrieval and GPT-2 for generation. This project helped us understand the fundamental principles of RAG and see it in action.
We probably got a little bit smarter about what RAG is and how it works 😇