
Kubernetes 1.29 Mandala: Essential Features & Security Enhancements
In Kubernetes 1.29 release named Mandala The Universe, there are 49 enhancements: 19 at Alpha stage, 19 now in Beta, and 11 reaching Stable maturity.
In this post, we'll highlight several interesting features and enhancements, at least in my opinion
Feature: Sidecar Containers Enhancement
Stage: Kubernetes v1.29 [beta]
- Background: Historically, all containers in a pod were started in parallel without any specific order. Kubernetes did not provide native mechanisms to control the startup, shutdown, or restart order of containers within a pod. Applications that relied on Sidecar Containers for essential services (like logging, monitoring, or networking) sometimes faced issues due to the lack of synchronization in the startup and shutdown processes.
- Key Changes: Enhanced initiation and termination processes to ensure uninterrupted support and optimized dependency management.
- KEP: KEP-753: Sidecar Containers
Example:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
initContainers:
- name: my-sidecar
image: my-sidecar-image:latest
restartPolicy: Always
containers:
- name: my-main-container
image: my-main-image:latest
❗Before the main containers of the pod are started, the Sidecar Containers commence their operation. This is ensured by defining them in the initContainers section with a restartPolicy of Always.
The following diagram is showing when the sidecar is being started and terminated:
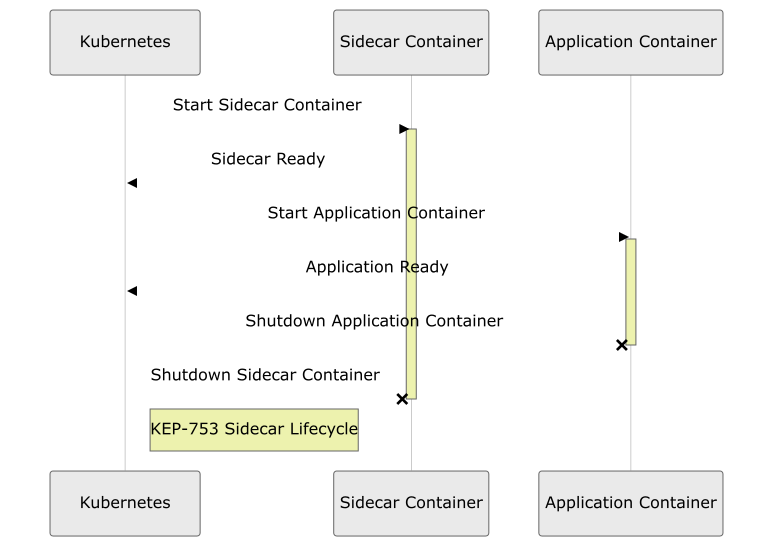
- Initialization of Sidecar Containers: When a pod is started, the Sidecar Containers defined in the
initContainerssection with arestartPolicyofAlwaysare initiated first. - Main Containers Start: After the initialization and successful startup of all Sidecar Containers, the main containers of the pod begin their startup process.
- Continuous Running of Sidecar Containers: Throughout the lifecycle of the main containers, the Sidecar Containers continue running, providing necessary support like logging, monitoring, or network proxy functions.
Termination Sequence:
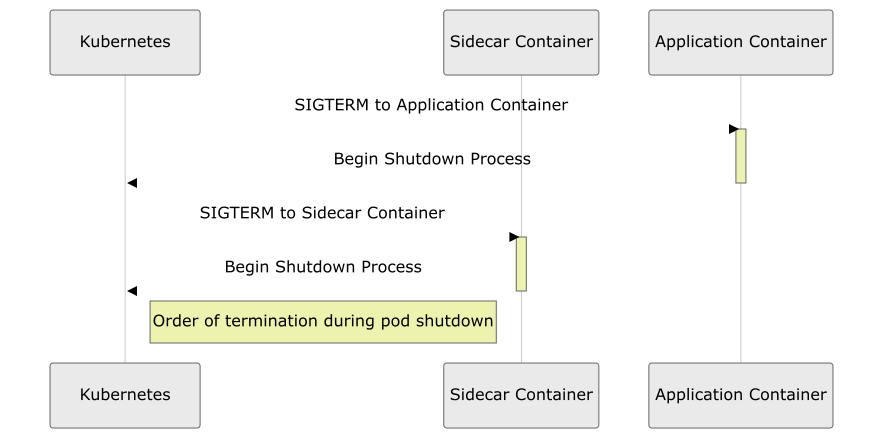
- Main Containers Termination: When a pod is terminated, the main containers begin their shutdown process first.
- Delayed Termination of Sidecar Containers: The Sidecar Containers continue to run even after the main containers have started their termination process. This ensures that any support or dependencies provided by the Sidecar Containers are available until the very end.
- Reverse Order Termination: The Sidecar Containers are terminated in the reverse order of their startup. This step is crucial for managing dependencies correctly and ensuring a smooth shutdown process.
- Complete Pod Shutdown: Once all Sidecar Containers have successfully terminated, the pod reaches its complete shutdown state.
Feature: In-Place Update of Pod Resources
- Background: Prior to this feature, changing resource allocations typically required restarting the pod, which could lead to service disruption. With in-place updates, resource changes can be made without restarting the pod or its containers, thus minimizing disruptions to running applications. For example, during peak usage times, resources can be increased to maintain performance, and then decreased during off-peak hours to conserve resources.
- Key Changes: Introduction of mutable pod specs, enabling dynamic resource adjustments without pod restart.
- KEP: KEP-1287: In-place update of pod resources
Example:
kubectl patch pod my-pod -p '{"spec":{"containers":[{"name":"my-main-container","resources":{"limits":{"memory":"512Mi"}}}]}}'
This command dynamically adjusts the memory limit of my-main-container to 512Mi without restarting the pod.
Feature: Improved Pod Status Information
- Background: Kubernetes 1.29 includes new fields in the pod status to support dynamic resource allocation changes. These fields provide more detailed information about resource usage and changes.
-
Key Changes:
- Allocated Resources Field: Provides a real-time snapshot of the resources currently allocated to the pod, reflecting the Kubernetes system's actual resource allocation.
- Resources Field: Shows the actual resources the pod is using, which is essential for understanding the real-time resource consumption and ensuring efficient resource utilization.
- Resize Field: This field tracks the ongoing resource resizing operations, indicating whether a resource change request is in progress, completed, or encountering any issues. It categorizes the resize status into stages like proposed, in progress, deferred, or infeasible.
- Container Resize Policy: A new policy that allows for more nuanced control over how resource allocation changes are applied to containers, specifying the conditions under which containers can have their resources adjusted without the need for a restart.
Examples of queries to get the introduced Pod Status Information:
-
Query for Allocated Resources Field:
kubectl get pod [POD_NAME] -o=jsonpath='{.status.allocatedResources}'This query retrieves the allocated resources for a specific pod. Replace
[POD_NAME]with the name of your pod -
Query for Resources Field:
kubectl get pod [POD_NAME] -o=jsonpath='{.status.resources}'Use this query to check the actual resources currently being used by a pod. Ensure to replace
[POD_NAME]with the actual name of your pod. -
Query for Resize Field:
kubectl get pod [POD_NAME] -o=jsonpath='{.status.resize}'This command helps you track the status of any ongoing resource resizing operations in a pod. Replace
[POD_NAME]with the name of the relevant pod. -
Query for Container Resize Policy:
kubectl get pod [POD_NAME] -o=jsonpath='{.spec.containers[*].resizePolicy}'This query will display the container resize policy for each container in the pod. Substitute
[POD_NAME]with the name of your pod.
Feature: Improved Reliability of Ingress Connectivity
Stage: Kubernetes v1.29 [beta]
- Background: Effectively managing network traffic is vital, especially in cloud environments. Kubernetes relies on kube-proxy to handle network routing within clusters, ensuring smooth communication between services and external sources. As Kubernetes clusters grow and operate in more dynamic and diverse environments, particularly in the cloud, the demand for more sophisticated network traffic management increases.
- Key Changes:
- Refinements in kube-proxy for Enhanced Network Traffic Management: Kubernetes 1.29 introduces significant refinements in kube-proxy, focusing on improving ingress connectivity. These changes include:
- Enhanced Connection Draining: Improvements to the way kube-proxy manages connection draining during node termination, providing a more stable network experience during scaling operations and reducing service disruptions.
- Improved Traffic Routing: Advanced traffic routing capabilities, especially in scenarios involving scaling down of resources, to ensure efficient load balancing and reduced latency.
- Better Integration with Cloud Environments: The updates cater specifically to the challenges and requirements of cloud-based Kubernetes deployments, offering enhanced compatibility and performance with cloud-native network infrastructures.
Feature: Priority and Fairness for API Server Requests
Stage: 1.29 [stable]
- Background: In Kubernetes, the API server plays a critical role as the central management entity for all operations within the cluster. It handles a wide range of requests, from creating and updating resources to fetching data. However, without an effective mechanism to prioritize these requests, critical system functions could be at risk of being delayed or overlooked due to less important requests, leading to potential system overload or inefficiency.
- Key Changes: Kubernetes 1.29 introduces a system to categorize and prioritize requests to the API server. This feature, now stable, ensures that critical system functions and requests essential for cluster health and management are not overshadowed by less important ones. Key aspects include:
- Request Categorization: Requests are categorized to distinguish between critical system functions and less crucial operations.
- Request Prioritization: This mechanism prioritizes essential functions, like node heartbeat updates, Kubernetes internal operations, and system maintenance tasks.
- Fairness in Request Handling: Beyond prioritizing critical requests, the system also maintains fairness, ensuring a balanced distribution of resources across various types of requests.
- Prevention of Server Overload: By managing request prioritization and fairness, the feature helps prevent scenarios where excessive demand could lead to server overload.
- More information: https://github.com/kubernetes/enhancements/tree/master/keps/sig-api-machinery/1040-priority-and-fairness
Feature: Reduction of Secret-based Service Account Tokens
Stage: Kubernetes v1.29 [beta]
Background: Service accounts in Kubernetes are used for assigning identities to workloads running in pods, providing a means for these workloads to access the Kubernetes API securely. Traditionally, these service accounts were authenticated using tokens stored as Kubernetes Secrets. However, this method had certain security drawbacks due to the broad accessibility and potential for misuse of these secret-based tokens.
- Key Changes:
- Reduction of Secret-based Service Account Tokens: In Kubernetes 1.29, there's a significant change in how service account tokens are managed, enhancing security and reducing the reliance on secret-based tokens.
- Transition to Bound Service Account Tokens: The update involves a move towards using the TokenRequest API and storing tokens as a projected volume instead of as traditional Secrets. This change was first introduced as GA in Kubernetes 1.22 and has been further refined in subsequent versions.
- Projected Volume for Token Storage: Service account tokens are now obtained via the TokenRequest API and stored as a projected volume. This method isolates the token in a more controlled environment, reducing the risks associated with the broader accessibility of Secrets.
- Lifecycle Management: The lifecycle of these tokens is now directly linked to the pod, providing improved security. This means the tokens are automatically created and destroyed with the pod, reducing the risk of stale or unused tokens lingering in the system.
- Reduction of Secret-based Service Account Tokens: In Kubernetes 1.29, there's a significant change in how service account tokens are managed, enhancing security and reducing the reliance on secret-based tokens.
- More Information: https://github.com/kubernetes/enhancements/tree/master/keps/sig-auth/2799-reduction-of-secret-based-service-account-token
Feature: Structured Authorization Configuration
Stage: Kubernetes v1.29 [Alpha]
- Background: Historically, the configuration of authorization mechanisms for the API server, particularly for complex setups involving multiple authorization sources (like webhooks), was managed using command-line flags. This approach had limitations in terms of flexibility and scalability, especially in large or complex environments.
- Key Changes:
- Introduction of Structured Authorization Configuration: Kubernetes 1.29 introduces a more structured and flexible approach to configuring authorization for the API server.
- Configuration File-Based Approach: Instead of relying solely on command-line flags for setting up authorization, administrators can now use configuration files. This change allows for more nuanced and complex authorization setups.
- Enhanced Flexibility and Control: The new configuration method enables administrators to define a sequence of authorization checks in a more manageable and readable format. For example, multiple webhooks can be specified in an ordered sequence for processing authorization decisions.
- Complex Authorization Scenarios: This structured approach is particularly beneficial for environments that require complex authorization logic, such as multi-tenant clusters or clusters with sophisticated security requirements.
- Introduction of Structured Authorization Configuration: Kubernetes 1.29 introduces a more structured and flexible approach to configuring authorization for the API server.
- More info: https://github.com/kubernetes/enhancements/issues/3221
Feature: ReadWriteOncePod PersistentVolume Access Mode
Type: Kubernetes v1.29 [Graduating]
Background: Efficient and secure management of storage is a crucial aspect of Kubernetes. Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) are key components in Kubernetes storage architecture, providing a way to manage storage resources in a cluster. Traditionally, Kubernetes supported various access modes for PVs, but there was a limitation in terms of restricting access to a single pod within a node, which could lead to data conflicts or security issues in certain scenarios.
Key Changes:
- Introduction of ReadWriteOncePod Access Mode: Kubernetes 1.29 introduces a new access mode for Persistent Volumes, named
ReadWriteOncePod.- Purpose: This access mode allows a PV to be mounted as read-write by a single pod. Unlike the existing
ReadWriteOnceaccess mode, which restricts a volume to a single node,ReadWriteOncePodrestricts it to a single pod within that node. - Use Cases: It's particularly useful for workloads that need a guarantee that the volume is being accessed only by a single pod, even if multiple pods are scheduled on the same node. This is crucial for data integrity and security.
- Implementation: When a PVC with this access mode is used by a pod, Kubernetes ensures that the volume is exclusively attached to the pod, preventing other pods from using the same PV even if they are on the same node.
- Purpose: This access mode allows a PV to be mounted as read-write by a single pod. Unlike the existing
Feature: Support paged LIST queries from the Kubernetes API
Stage: Kubernetes v1.29 [Stable]
- Background: Traditionally, retrieving large resource lists from the API server in a single request could strain system resources due to the extensive memory allocation required.
- Key Changes:
- Introduction of Paged List Queries: Kubernetes 1.29 introduces the ability to perform paged list queries to the Kubernetes API.
- Efficient Data Retrieval: This feature allows API consumers to fetch large sets of data in paginated responses. By breaking down a large list request into multiple smaller requests, it significantly reduces the impact on memory allocation.
- Scalability and Performance: The enhancement dramatically improves the scalability of the Kubernetes API, making it more efficient and reliable in handling extensive data sets.
- More information: https://github.com/kubernetes/enhancements/issues/365
Examples of how to make queries with paging:
The following command fetches pods information in pages, with each page containing up to 50 pods:
kubectl get pods --chunk-size=50Direct Kubernetes API Requests:
If you are using the Kubernetes API directly, you can utilize the limit and continue parameters in your API query.
The limit parameter specifies the maximum number of items to be returned in a single page.
The continue parameter is used for fetching the next set of results. It should be set to the value of the metadata.continue field from the previous result set:
GET /api/v1/namespaces/default/pods?limit=50The following request fetches the first 50 pods in the 'default' namespace.
The response includes a metadata.continue field, which you use in the next query to get the next page of results:
GET /api/v1/namespaces/default/pods?limit=50&continue=<continue-token>
Replace <continue-token> with the actual token you received from the previous response.
Where is the information about the features and enhancements retrieved from?
I'm following the 1.29 Enhancements Tracking page:
https://github.com/orgs/kubernetes/projects/161/views/1
About the Author
Aleksandro Matejic, a Cloud Architect, began working in the IT industry over 21 years ago as a technical specialist, right after his studies. Since then, he has worked in various companies and industries in various system engineer and IT architect roles. He currently works on designing Cloud solutions, Kubernetes, and other DevOps technologies.
In his spare time, Aleksandro works on different development projects such as developing devoriales.com, a blog and learning platform launching in 2022/2023. In addition, he likes to read and write technical articles about software development and DevOps methods and tools.
You can contact Aleksandro by visiting his LinkedIn Profile

Thanks Carlos for your feedback.
I also find this aspect particularly interesting. Implementing a sidecar container as an initContainer is indeed an interesting design choice. It's a really nice improvement though and gives a better control of when things happen compared to how it used to be without really any control of which container will go up or down first.